Code Generation
Code generation is a great way to apply patterns consistently across a solution or to create multiple similar classes based on some outside input file, or even other classes in the same solution. The tooling has changed over the years, but the result is the same… a lot of code that I don’t have to write by hand, or update when patterns change and evolve.
I’ve been generating source code since the early days of .Net 1.0 when we used some plug-ins to generate source code based on class diagrams drawn in Visio. It worked, but it was a one-way trip because .Net didn’t have partial classes yet. We left that behind pretty quickly for a tool from Borland called “Together” that kept our code and diagrams in sync as you worked directly on either half. It was pretty awesome, but Together kind of died out when the price suddenly skyrocketed for version 2.0.
Then, somewhere around the Visual Studio 2008 timeframe I discovered T4 templates. A coworker had written a command-line program to generate mockable testing shims around Linq to SQL contexts, and I adapted it to run inside a T4 template so that we wouldn’t have to keep running it by hand and copying the results into our solution by hand every time we made a change to our models. These templates were stored as artifacts in our solution, and added code directly to our projects which was a big win. I was hooked, and used this approach to eliminate other repetitive coding tasks such as creating Builder classes for testing support, which is still my primary use case today.
T4 templates became untenable with the release of .Net Core, or at least the way I was using them, because the reflection code that I relied on no longer worked. T4 templates run under the full framework and cannot reflect over .Net Core code, or at least they couldn’t at the time.
I moved on to Roslyn templates and a project called “Scripty.msbuild” to transform them at build time. The .csx files that drove this approach did their job very well, and I was happy with how they worked. I could keep my reflection-based code mostly intact because I was just swapping out the runner. Unfortunately, Scripty was more or less abandoned in 2017, and when it started having some problems as well, I needed a new alternative.
Next, I tried using TypeWriter to generate my Builder code. TypeWriter was meant for creating javascript equivalent DTOs out of .Net code, but it can be used to create any kind of text file. Still, it’s clearly focused on emitting javascript and TypeScript, so more work was needed to get it to generate .Net code.
Most recently, I was back to using T4 again, but without the reflection part. The T4 engine still works just fine. We just need a different input than reflection if we’re going to use it on a .Net Core project. My current project is using an external designer to create the business entities, much like Visio and Together did back in the day. The XML file from this designer is used as the input for the templates instead of reflection, so T4 seems to be working just fine.
That’s great, and solves our problem in newer code, but the writing on the wall seems clear that T4 templates are not a thing Microsoft is interested in developing any further, and I imagine they’ll just go out of style completely at some point now that we have .Net Source Generators.
Source Generators run inside Visual Studio and can generate code in real time as you work, which makes them a lot easier to work with than the systems that came before them. They’re implemented as Visual Studio analyzers, which you’d normally use to do things like putting squiggly underlines in the code to suggest changes, and maybe even implementing “quick fixes” to make those changes for you. Source Generators take this a step further and let you create entirely new code that becomes part of the project, and not just at compile time. The code that generators create is available immediately. You can reference the generated code in your own classes, even in the same project, without having to recompile everything first.
It’s not all perfect though. The mechanism is still pretty young, and the Visual Studio experience is in its early days, so the process of creating a Source Generator isn’t totally smooth yet, but once you’ve written your generator, the act of using it is pretty painless.
Planning
The first step in generating code is, counterintuitively, to write that code by hand. Start by trying to write the thing you intend to generate and make sure it works the way you expect. Work out any kinks or problems and take it for a test drive before trying to automate it. Hash the idea out before creating a factory to mass produce it. It’s usually easier to write code than it is to write code that writes code.
The ideal candidate for generated code is a pattern that you’ve nailed down already and grown tired of writing over and over again. If you find yourself saying “I never want to write another {thing}” again, then that thing might be an ideal candidate for generation.
As you progress along, compare your generated output to the example class you started with in order to identify the parts that aren’t coming out quite right or that you haven’t finished yet. Tackle a feature at a time, and when your generator can output the same (or similar-enough) code to what you wrote by hand, then you’ll know you’re done.
For this demo, I won’t make you watch the entire process of evolving the whole system in real-time, so I’ll be jumping ahead quite a bit as we go. Just know that this is how my example was developed, one piece at a time.
First Steps
Create a new class library project to hold the source generator itself. I’m calling mine “BuilderGenerator”. This project doesn’t need to target a specific framework version, so either choose “netstandard2.0” when creating the project, or alter the TargetFramework node in the csproj file as follows. At the time I wrote this, you still had to specify the language version as “Preview” as well, although that may not be the case by the time you read this.
In addition, you’ll need references to the Microsoft.CodeAnalysis.CSharp and Microsoft.CodeAnalysis.Analyzers packages. You can do this through Visual Studio’s NuGet package manager which might find a newer version, or you can copy and paste these in from the example below and then go look for updates. The choice is yours.
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
<LangVersion>preview</LangVersion>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.CodeAnalysis.Analyzers" Version="3.3.2" PrivateAssets="All" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp" Version="3.9.0" PrivateAssets="All" />
</ItemGroup>
</Project>
Remember to save your project file before continuing, or Visual Studio may get confused. This project can now be used as a source generator. We just need to fill in something for it to generate. Let’s create our “BuilderGenerator” class. You can call this class anything you want, but I’ll name it the same as the project and solution just to keep things simple. Decorate it with the “Microsoft.CodeAnalysis.Generator” attribute, implement the “ISourceGenerator” interface, and you should end up with something that looks like this.
using System;
using Microsoft.CodeAnalysis;
namespace BuilderGenerator
{
[Generator]
public class BuilderGenerator : ISourceGenerator
{
public void Initialize(GeneratorInitializationContext context)
{
throw new NotImplementedException();
}
public void Execute(GeneratorExecutionContext context)
{
throw new NotImplementedException();
}
}
}
Rather than throwing exceptions at runtime, which won’t get us very far, let’s start building out some code. We’ll start off small, and generate a class that says “Hello World!”.
using System.Text;
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.Text;
namespace BuilderGenerator
{
[Generator]
public class BuilderGenerator : ISourceGenerator
{
public void Initialize(GeneratorInitializationContext context)
{
// Nothing to do... yet.
}
public void Execute(GeneratorExecutionContext context)
{
var greetings = @"using System;
namespace Generated
{
public class Greetings
{
public static HelloWorld()
{
return ""Hello World!"";
}
}
}";
context.AddSource("Greetings.cs", SourceText.From(greetings, Encoding.UTF8));
}
}
}
The work is done in the “Execute” method which is simply outputting a string containing the entire Greetings class contents to a file. This is the simplest form of code generation there is, simply adding pre-defined contents to the project that’s using the generator.
Using the Source Generator
Now that we have a source generator, albeit a boring one, let’s add it to a project to see it in action. Add a second project to the solution. I’m calling mine “Domain”. It will be taking the place of a typical domain layer and define some sample entities. This project can safely target a specific core framework version as usual. Edit the resulting csproj file to look like this:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netcoreapp3.1</TargetFramework>
<LangVersion>preview</LangVersion>
</PropertyGroup>
<ItemGroup>
<ProjectReference Include="..\BuilderGenerator\BuilderGenerator.csproj" OutputItemType="Analyzer" ReferenceOutputAssembly="false" />
</ItemGroup>
</Project>
Note that the reference to the BuilderGenerator project has some additional properties on it. The first is what tells Visual Studio that the referenced project is an analyzer, and not a library. The second property, “ReferenceOutputAssembly = ‘false'” states this even more explicitly. As of now, you can’t reference a project as both an analyzer and a library at the same time, although I’m hoping this might change in the future because it would make things like base classes or attributes easier to implement.
This new analyzer will generate code that lives in the Domain project itself, although your ability to see it may be limited. Support for viewing generated code is improving all the time, so depending on the vintage of your Visual Studio installation, it may or may not let you browse to the generated code easily. You can, however, make references to it from other classes and/or projects, so let’s see if we can find it. Add a unit test project to the solution. I’ll call mine “UnitTests”. Add a reference to the Domain project, and then create our first test, called “GreetingsTests”
using NUnit.Framework;
namespace UnitTests
{
[TestFixture]
public class GreetingsTests
{
[Test]
public void SayHello_returns_expected_string()
{
Assert.AreEqual("Hello World!", Generated.Greetings.HelloWorld());
}
}
}
Depending again on your version of Visual Studio, you may see some Intellisense errors at this point, and may have to restart Visual Studio before continuing. It appears to me that Visual Studio loads up the analyzer once, when loading the solution, and will keep using that analyzer for the rest of that session. This may or may not accurately describe what is really going on behind the scenes, but it’s certainly the effect I observed. Any time I made a change to the generator itself, I’d have to restart Visual Studio to take advantage of the changes.
Once the generator itself is finished, you should be able to go about using it “live” without any problems, but the process of working on the generator itself may be a bit of a chore. If you run into this problem, restart Visual Studio and Intellisense should start working again, including auto-complete. Hopefully these errors will go away in later releases and by the time you read this, it may have been solved once and for all.
Generating Real Code
Now that we have a working source generator, let’s make it do something more useful than returning “Hello World”. I’ve posted several times in the past about my love of the Builder pattern, and how it can help make your tests easier to write and also easier to read, communicating their intent more clearly to other developers. Since this is a pattern that I have implemented using just about every available source generation system in .Net, it seems like a natural choice for my first Source-Generator-based project.
Let’s start simply. For each entity class (e.g. User), we want to generate a corresponding “Builder” class (e.g. UserBuilder). The contents aren’t important yet, just that we can generate the builder class, and that we can refer to it from other classes within the same project, or from the tests.
First, we’ll create an attribute to mark the classes we want to generate builders for. Unfortunately, we can’t just define the attribute in the BuilderGenerator project itself. Our Domain project is referencing the BuilderGenerator project, but it’s doing it as an Analyzer, not as a library, so we can’t make direct use of the classes defined there. Instead, we can either create another project to house the attribute and other common elements such as base classes, or we can have the generator simply output the attribute class the same way we generated the Greetings class above. In fact, we can simply replace the existing contents of the BuilderGenerator class to emit this new attribute class instead.
using System.Text;
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.Text;
namespace BuilderGenerator
{
[Generator]
public class BuilderGenerator : ISourceGenerator
{
public void Initialize(GeneratorInitializationContext context)
{
// Nothing to do... yet.
}
public void Execute(GeneratorExecutionContext context)
{
var attribute = @"namespace BuilderGenerator
{
[System.AttributeUsage(System.AttributeTargets.Class)]
public class GenerateBuilderAttribute : System.Attribute
{
}
}";
context.AddSource("GenerateBuilderAttribute.cs", SourceText.From(attribute, Encoding.UTF8));
}
}
}
We’ll reuse this same mechanism to generate any other attributes or base classes that we need.
Next, in the Domain project, create a folder to hold our entity definitions. I’ll call mine “Entities”. Create a new entity called “User” in the “Entities” folder, give it a couple properties, and decorate it with the “GenerateBuilder” attribute which should already be available if everything is working properly.
using BuilderGenerator;
namespace Domain.Entities
{
[GenerateBuilder]
public class User
{
public string FirstName { get; set; }
public string LastName { get; set; }
}
}
Again, the contents are not important at this stage. We just want something to generate a builder for. Since this is not a tutorial on Roslyn syntax, I won’t get too deep into the workings here, but we’re going to want what’s called a “SyntaxReceiver”, which acts as a kind of filter, sorting through the syntax tree that represents all of the code for our project, and forwarding the parts we’re interested in to our generator. Add a new class called “BuilderGeneratorSyntaxReceiver” with the following contents.
using System.Collections.Generic;
using System.Linq;
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp.Syntax;
namespace Generator
{
internal class BuilderGeneratorSyntaxReceiver : ISyntaxReceiver
{
public List<ClassDeclarationSyntax> Classes { get; } = new();
public void OnVisitSyntaxNode(SyntaxNode syntaxNode)
{
if (syntaxNode is ClassDeclarationSyntax classDeclaration && classDeclaration.AttributeLists.Any(x => x.Attributes.Any(a => a.Name + "Attribute" == "GenerateBuilderAttribute"))) Classes.Add(classDeclaration);
}
}
}
The name isn’t actually important, but we’ll name it for the generator it serves to keep it clear. This filter looks for any classes in the syntax tree with the GenerateBuilder attribute on them, and adds them to a list called “Classes”.
Replace the contents of the BuilderGenerator.Execute method with the following:
public void Execute(GeneratorExecutionContext context)
{
if (context.SyntaxReceiver is not BuilderGeneratorSyntaxReceiver receiver) return;
foreach (var targetClass in receiver.Classes.Where(x => x != null))
{
var targetClassName = targetClass.Identifier.Text;
var targetClassFullName = targetClass.FullName();
var builderClassNamespace = targetClass.Namespace() + ".Builders";
var builderClassName = $"{targetClassName}Builder";
var builderClassUsingBlock = ((CompilationUnitSyntax) targetClass.SyntaxTree.GetRoot()).Usings.ToString();
var builder = $@"using System;
using System.CodeDom.Compiler;
{builderClassUsingBlock}
using Domain.Entities;
namespace {builderClassNamespace}
{{
public partial class {builderClassName} : Builder<{targetClassName}>
{{
// TODO: Write the actual Builder
}}
}}";
context.AddSource($"{targetClassName}Builder.cs", SourceText.From(builder, Encoding.UTF8));
}
}
There are a few things going on here. First, we make sure that we’re only paying attention to the classes that have passed through the SyntaxReceiver we defined earlier. For each class that passes the filter, which I’ve called a “target class”, we extract some basic information, and inject it into a template in order to create a builder class, which is then added it to the consuming project. That class is empty for now because our first goal is to simply generate a builder for each decorated entity class.
Since we’ve made changes to the generator itself, you may need to restart Visual Studio before it starts using the new version, but if everything is working properly, a new class called UserGenerator be added to the Domain project. Just like with the attribute, this file won’t appear in the Solution Explorer, but is should appear in the Class View, under Domain.Entities.Builders, and if you double-click to open it, you should see a new “UserBuilder” class with a comment that says “TODO: Write the actual Builder”.
You can already reference this class in your other code such as in unit tests. Delete the old GreetingsTests class, and replace it with a new “BuilderTests” class that looks like this:
using Domain.Entities.Builders;
using NUnit.Framework;
namespace UnitTests
{
[TestFixture]
public class BuilderTests
{
[Test]
public void UserBuilder_exists()
{
var actual = new UserBuilder();
Assert.IsInstanceOf<UserBuilder>(actual);
}
}
}
Now that we have the skeleton of our builder being generated, we’ll want to start filling in the parts that make it work, starting with the backing properties for the target class’ public properties. We start by pulling the list of settable properties from the target class, and adding a property to the builder for each one. Add the following just after the declaration of targetClassFullName in the Execute method.
var targetClassProperties = targetClass.DescendantNodes()
.OfType<PropertyDeclarationSyntax>()
.Where(x => x.IsInstance() && x.HasSetter())
.ToArray();
Then, replace the TODO comment with a call to a new method called “BuildProperties”.
public partial class {builderClassName} : Builder<{targetClassName}>
{{
{BuildProperties(targetClassProperties)}
}}
And finally, define the BuildProperties method as follows.
private static string BuildProperties(IEnumerable<PropertyDeclarationSyntax> properties)
{
var result = string.Join(Environment.NewLine,
properties.Select(x =>
{
var propertyName = x.Identifier.ToString();
var propertyType = x.Type.ToString();
return @" public Lazy<{propertyType}> {propertyName} = new Lazy<{propertyType}>(() => default({propertyType}));"
}));
return result;
}
I like to make my backing properties Lazy<T> because they don’t just hold the final property value of the completed object. Builders represent the plan for how to build that object, and plans are subject to change. Using a lazy value means that the code to set the final value won’t run until the object is built at runtime.
Next Steps
I’m not going to make you read through the entire evolution of my Builder pattern here because it’s only one specific use case, but the next step would be to add a method called “Build” that creates the final object, and a set of convenience methods to support a fluent interface. If you want to see the code that makes up my own BuilderGenerator, you can find the project source on its GitHub page.
There are many different examples of Builder classes out there, and some are more complicated than others, but that’s the beauty of code generation. If I expand on my pattern, to add new features, I only have to update the template, and the changes will be reflected across all my classes, or even across all my projects.
What I’ve shown here demonstrates the basic scaffolding of a Source Generator, and how to drive that generator’s output using the existing code in a project. From here, you would iteratively add a feature at a time until the generated code matches the hand-written example you started from. You can follow this pattern to generate any kind of highly-repetitive code that you want in your projects.



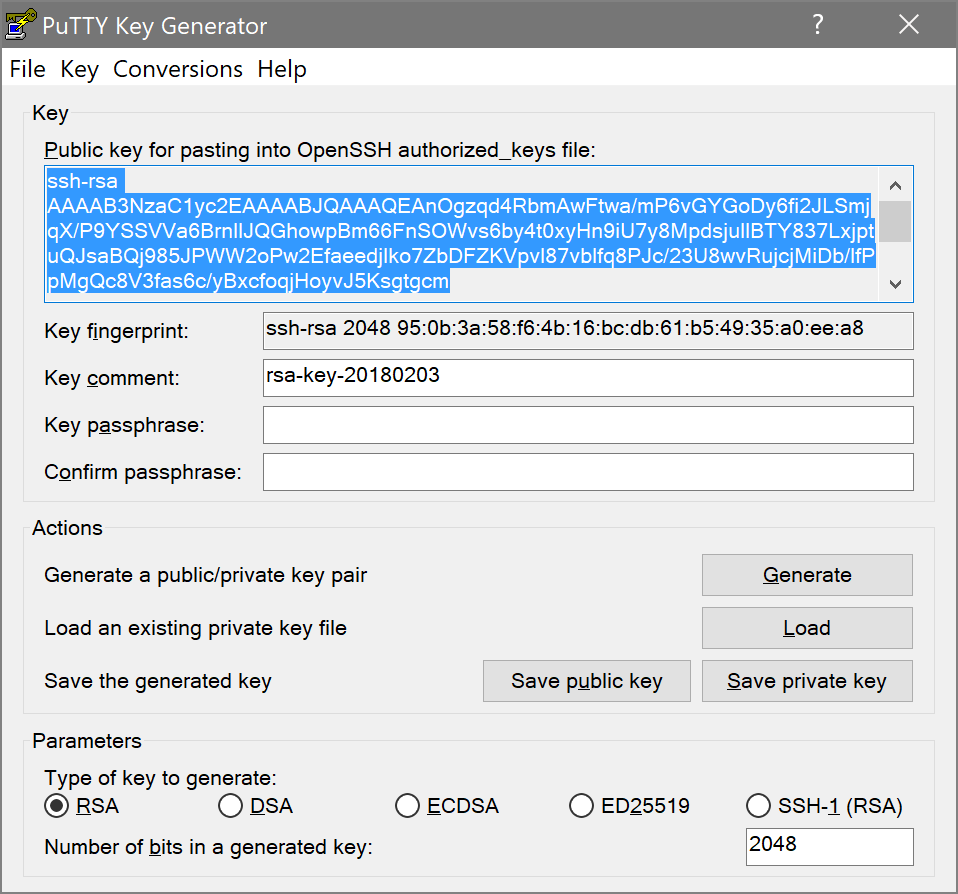
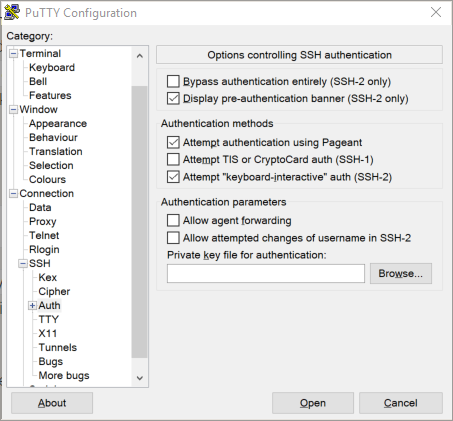 Click the “Browse” button, and then go find the id_rsa file in your .ssh folder. Scroll the left-hand section back up to the top, and click on Session. Give the new session a name, and save it. If you loaded an existing session, then clicking Save will update it. Either way, PuTTY should remember the private key now. Click “Open”, and you should get a login prompt as usual, but after you enter the username, you won’t be prompted for a password. That’s it. You’re authenticating using keys.
Click the “Browse” button, and then go find the id_rsa file in your .ssh folder. Scroll the left-hand section back up to the top, and click on Session. Give the new session a name, and save it. If you loaded an existing session, then clicking Save will update it. Either way, PuTTY should remember the private key now. Click “Open”, and you should get a login prompt as usual, but after you enter the username, you won’t be prompted for a password. That’s it. You’re authenticating using keys.